新闻动态



近日,复旦大学工程与应用技术研究院(简称工研院) 机器人智能实验室(简称ROILAB)的2篇论文:《Correspondence Transformers with Asymmetric Feature Learning and Matching Flow Super-Resolution》(下简称 ACTR)、 《MISC210K: A Large-Scale Dataset for Multi-Instance Semantic Correspondence》(下简称 MISC210K)的学术论文被人工智能顶级会议CVPR 2023录用,工研院2021级硕士生孙翊轩为2篇论文的第一作者,张文强研究员与戈维峰副研究员为论文的通讯作者。
图像的语义匹配研究旨在训练一个计算机模型,使其可以像人一样发现两个有相同语义物体间的局部语义区域一致性。不同于之前的匹配任务面向完全相同物体/场景,语义匹配任务旨在排除外观轮廓的干扰,仅关注语义之间的共性信息(如图1)。该方法可以被用于细粒度的图像理解,异构图像的配准,图像编辑,以及多种视频理解任务中。当前主要的数据集为 SPair-71K、PF-PASCAL 等单实例匹配数据集。

图1:图像的语义匹配任务示意图
论文1: ACTR 解决了仅使用稀疏注释来学习同一类别的不同对象实例之间密集视觉对应的问题。本文将复杂的像素级语义匹配问题分解为两个更简单的问题:1)将源图像和目标图像的局部特征描述符映射到共享语义空间以获得低精度的匹配场表征。 2)通过优化低分辨率的匹配场表征,来生成准确的点对点匹配结果。为解决上述问题,ACTR 提出了基于视觉转换器的非对称特征学习和匹配流超分辨率两个模块(如图 2)。非对称特征学习模块利用有非对称的交叉注意机制来编码源图像语义 token 及其对图像的语义 token。随后通过超分辨率网络增强低分辨率的匹配流以获得准确的对应关系。
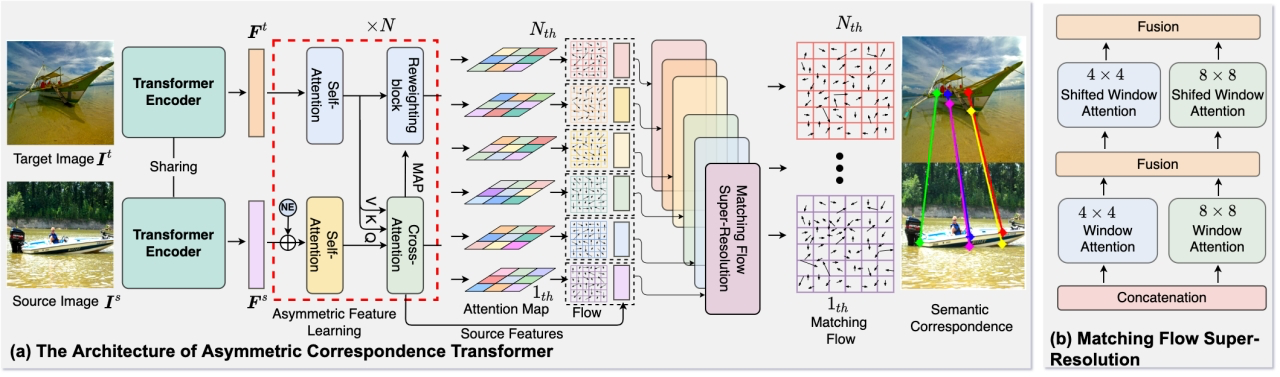
图2:ACTR 模型结构示意图

图3:ACTR 方法在 SPair-71K 数据集上的效果比较可视化
在 PF-PASCAL、PF-WILLOW 和 SPair-71K 等几个流行基准上的实验结果表明,所提出的方法可以有效地捕捉像素中细微的语义差异(如图 3)。
ACTR 提出的图像语义匹配方法可以有效地解决单实例图像间语义匹配问题。但是在真实场景中,多个有相同语义的实例往往是同时出现的。此外,匹配场景中,由于物体的位姿差异,源图像中出现的语义区域往往不能在目标图像中完全出现,这导致当前图像语义匹配方法与现实世界的应用仍有明显差距。
为了填补上述空白,论文2: MISC210K 研究了多实例语义匹配任务,该任务旨在构建图片对中多个对象之间的对应关系。论文从 COCO Detection 2017 任务构建了一个名为 MISC210K 的多实例语义匹配数据集。研究中将数据集构建为三个步骤:
类别选择和数据清理;
基于3D模型和物体描述规则的关键点设计;
人机协同标注。
按照这些步骤,MISC210K 数据集选择了 34 类对象,通过精心设计的半自动工作流程标注了 4812 张具有挑战性的图像,最终获得了 218,179 个图像对,其中标注了实例掩码和实例级关键点对。论文还提供了基准评估和进一步的消融结果以及详细的分析,并提出了三个多实例图像语义匹配未来的研究方向。
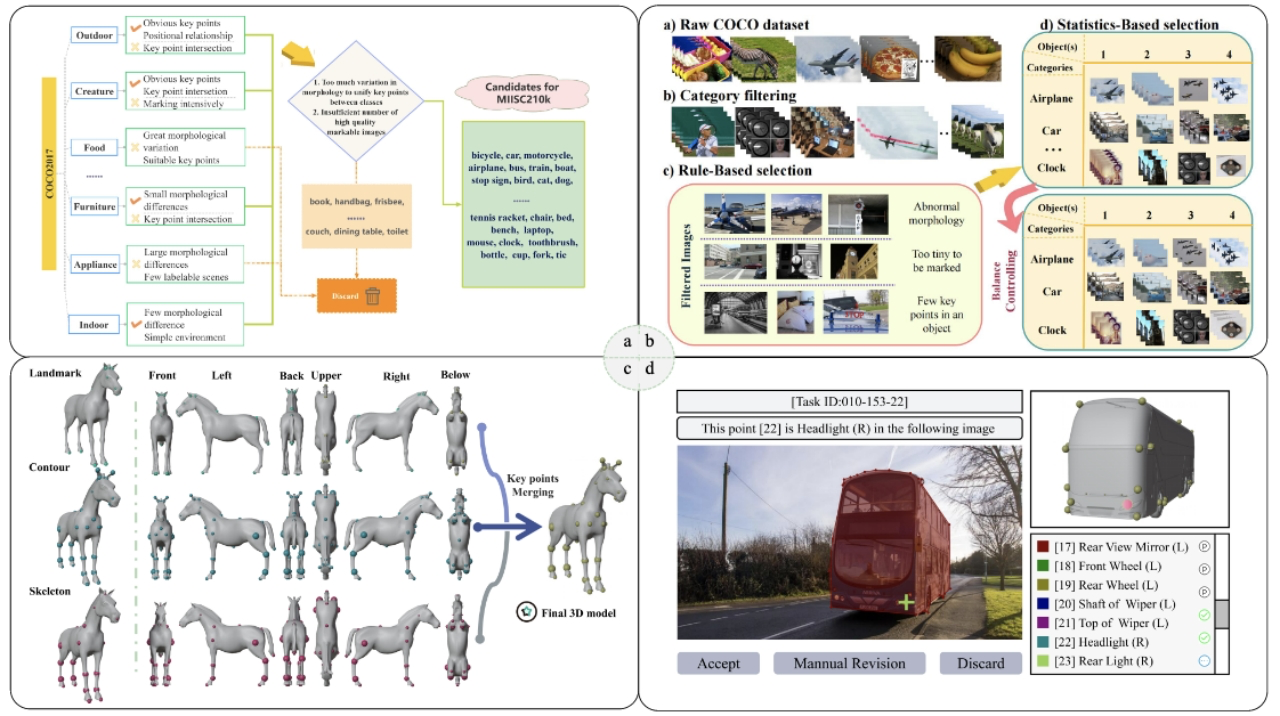
图4:MISC210K 数据集的标注流程与技术细节
上述研究成果在ROILAB实验室的异构医学影像配准、开放域场景识别等领域开展了示范应用和落地。
地址:上海市杨浦区邯郸路220号 邮编:200433 电话:(86)021-65642222
Copyright©2016复旦大学版权所有 沪ICP备:16018209
 工研院二维码
工研院二维码
 研究生会二维码
研究生会二维码