新闻动态



近日,复旦大学工程与应用技术研究院(以下简称“工研院”)机器人智能实验室最新研究研究成果——题为“Adaptive Online Mutual Learning Bi-decoders for Video Object Segmentation”的论文被期刊《IEEE Transactions on Image Processing》(TIP)接收。第一作者为工研院直博生郭品学,通讯作者为张文强研究员和张巍副教授。TIP是计算机视觉领域的顶级国际期刊(CCF A类,中科院1区TOP,影响因子11.041),要求发表的论文在理论和工程应用方面对图像处理及相关领域有重要推动作用。
视频目标分割(Video Object Segmentation, VOS)是计算机视觉领域的一个基础问题,旨在对视频中的目标物体进行持续、像素级的分割,被广泛应用在自动驾驶、视频编辑、机器人等领域。现有方法仍面临严重的训练数据和测试数据之间的数据分布差异问题,包括测试视频序列中未见过的物体类别、物体剧烈变形以及外观随时间的不断变化。张文强团队提出了自适应在线互学习双编码器框架(Adaptive Online Mutual Learning Bi-decoders, AOML)来解决上述问题。
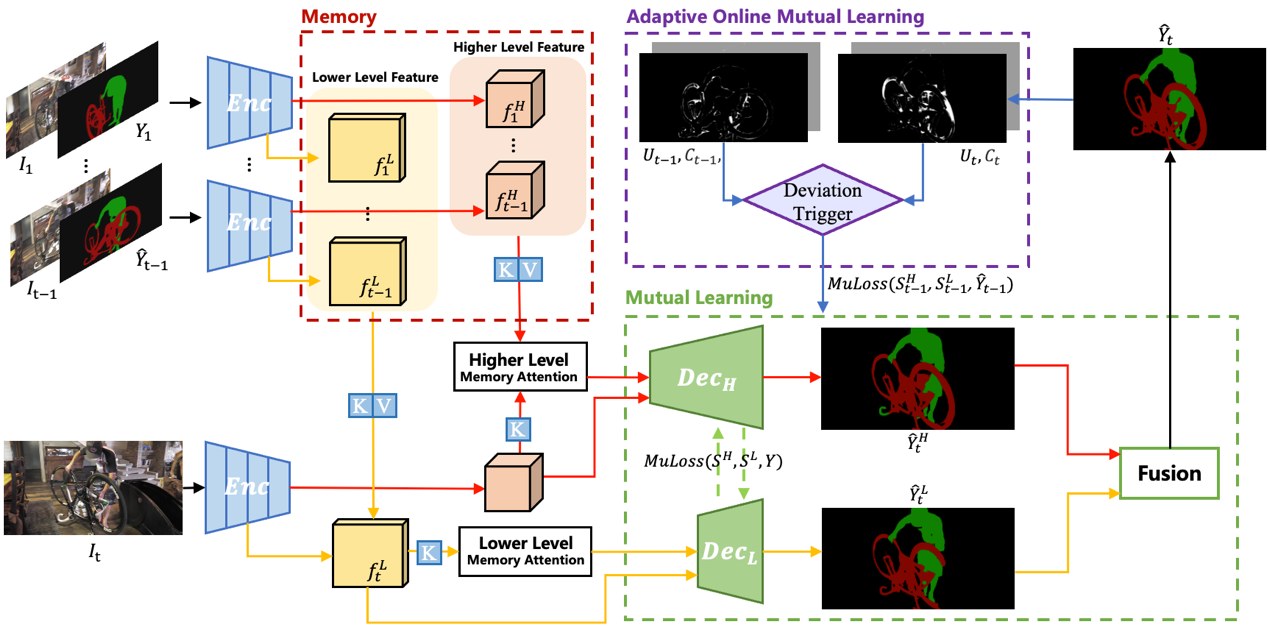
图 1 自适应在线互学习双编码器算法框架AOML
在双解码器互学习框架中,使用双层注意力机制提取物体特征,然后将它们输入到互学习双解码器中,融合两者输出获得最终的分割结果。低层特征包含更多的目标细节,高层特征有更强的语义信息,本文将从双解码器得到的不同分割结果图之间的分歧(使用KL-divergence来衡量)定义为不确定性(uncertainty),并通过双解码器的相互学习来消除这种不确定性,这近似于消除预测结果和真实标注之间的偏差。因此,这样训练得到的模型具有更强的泛化能力,对未见过的类别也更加稳健。
此外,为了克服视频序列中外观剧烈变化的挑战,通过使用已经预测过的掩码进一步优化在线的双解码器,并使双解码器的输出之间的分歧最小化,从而使这些已经预测的分割结果对模型的在线学习是正确可靠的。为此,本文基于双编码器的不确定性设计了一个纠正偏差的触发器(deviation correcting trigger),在测试过程中,当触发器检测到某一帧分割的预测相对于前一帧的预测具有更高的不确定性时,会触发基于更可能准确的前一帧进行自适应在线互学习。因此,本文的算法框架能够在急剧变化的测试视频序列中发现并纠正潜在的错误,甚至对训练期间未见过的物体类别也能表现良好。
表 1 不同方法在DAVIS-2016上定量结果比较,(+Y)表示使用了额外的YouTubeVOS训练数据。
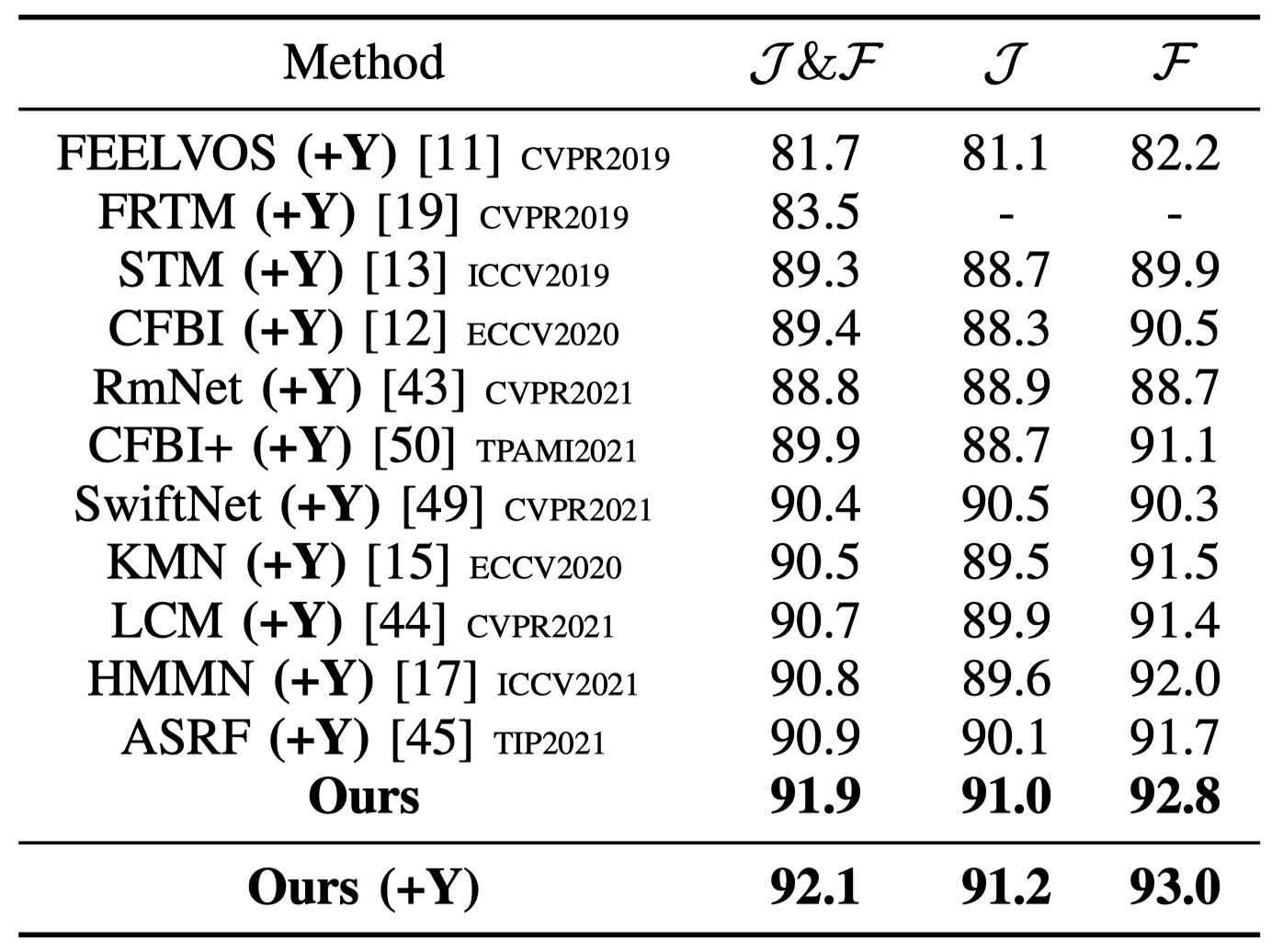
表 2本文方法和基线方法STM在不同测试基准上的定量结果比较。


图 2 引入/不引入自适应在线互学习机制的分割结果定性比较。
本文在VOS及相关领域广泛使用的基准测试数据集上进行了全面的对比实验和消融实验以评估所提方法,包括DAVIS2016、DAVIS-2017、YouTubeVOS-2018、YouTubeVOS-2019和UVO。实验结果表明:(1)本算法甚至只使用较小数据量的DAVIS数据集训练就可以达到甚至超过使用了额外大数据集YouTube(DAVIS数据量的50)训练的现有算法(见表1),另外在YouTube的unseen子集(训练集不包含的测试物体类别)和包含了大量新类别的UVO数据集上,本文方法相对基线方法STM的性能提升格外显著(见表2),证明了双解码器互学习的有效性。(2)本文所提算法性能在各个数据集均超过现有方法达到了最先进水平。在测试过程中,自适应在线互学习使模型能够处理相似物体遮挡、物体快速形变等难题而不产生错误累积(见图3)。证明了本文所提出自适应在线互学习机制的合理性及有效性。
地址:上海市杨浦区邯郸路220号 邮编:200433 电话:(86)021-65642222
Copyright©2016复旦大学版权所有 沪ICP备:16018209
 工研院二维码
工研院二维码
 研究生会二维码
研究生会二维码