新闻动态



近日,复旦大学工程与应用技术研究院(简称“工研院”)群体机器人系统实验室(Multi-AGent robotIC systems Lab,简称‘MAGIC Lab’)在计算语言学协会年会(Annual Meeting of the Association for Computational Linguistics,简称‘ACL’)上发表语言模型轻量化领域的最新研究成果。题为《Boost Transformer-based Language Models with GPU-Friendly Sparsity and Quantization》的学术论文被自然语言处理顶会ACL-2023录用,工研院2021级博士生余翀为第一作者,陈涛研究员和甘中学教授为通讯作者。
论文简介:
伴随着基于Transformer结构的自然语言模型(TLM)性能的提高,其模型参数规模也在急剧增加。先前的一些模型压缩工作能够将基于Transformer结构的语言模型压缩成更紧凑的形式,但并没有充分考虑到硬件特性可能不支持这些压缩格式的有效执行。这就导致如何在硬件上高效部署Transformer自然语言模型,并能够获得预期的明显加速效果这一问题仍然具有极大的挑战性。
本文设计了一个名为GPUSQ-TLM的压缩方案,来充分利用GPU可高效加速的稀疏与量化特性。该方案首先将原始Transformer自然语言模型在混合精度微调过程中进行结构化剪枝,以满足GPU对稀疏模式的加速约束;进一步通过量化感知训练将其量化压缩为一个定点模型,来最大限度地利用GPU对整数张量提供的额外加速。在剪枝和量化过程中,均采用混合策略对语言模型的预测标签、预测概率分布和特征图进行知识蒸馏,以获得最佳的精度补偿效果。实验结果表明,GPUSQ-TLM方案适用于各种基于Transformer编码器和解码器的自然语言模型高效压缩。并且压缩后的模型在SQuAD、GLUE、CNN-DM、XSum和WikiText基准测试任务上的精度下降可以忽略不计。此外,GPUSQ-TLM方案可以在A100 GPU上将自然语言模型实际延迟和吞吐的部署性能分别提高4.08-4.25倍和6.18-6.79倍。
本文主要工作:
基于Transformer结构的自然语言模型(TLM)因其具有的注意力机制和结构,故而特别擅长处理序列输入的远距离依赖关系。随后的研究表明,基于Transformer结构的预训练语言模型刷新了自然语言处理各项任务的榜单。如图1所示,伴随着其性能的提升,TLM模型的参数规模呈现出指数型增长的趋势。
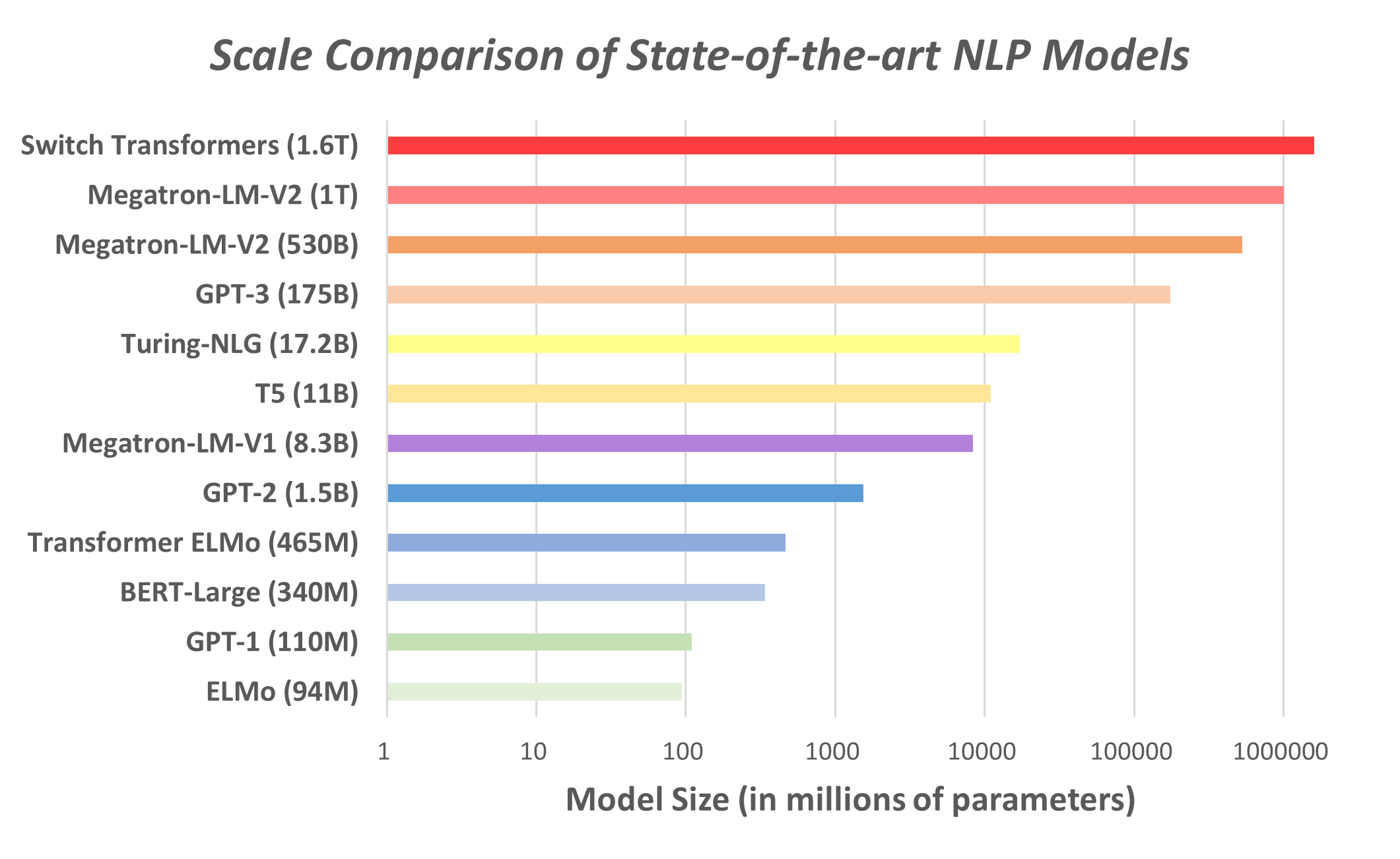
图1. 各种典型的自然语言模型参数规模对比
Transformer结构是TLM自然语言模型中的基本构件,对于典型的BERT模型和GPT-3系列模型,90%以上的模型权重参数和执行时间都集中在堆叠的Transformer结构块中。因此,对于TLM的性能提升,需要重点考量如何利用GPU支持的稀疏以及量化加速特性来压缩Transformer结构块。图2上部所示为TLM自然语言模型及分层缩放展示的Transformer结构块和多头注意力单元。其中,全网络的线性投影层,以及每个Transformer结构块中的前馈层和线性投影层,都是我们进行结构化稀疏压缩的目标层。图2下部橙色虚线框中所示为如何将一个稀疏压缩目标层的权重参数压缩成GPU所支持的结构化稀疏格式,并通过GPU中的稀疏张量运算核进行高效加速。同时为了进一步提升压缩模型的运行效率,我们对于结构化稀疏压缩的目标层同时引入低比特量化操作。我们还在结构化稀疏压缩的目标层前后分别插入了低比特量化模拟和反量化模拟操作节点,这样就可以通过量化感知训练的方式来最大程度地提升压缩模型的精度。
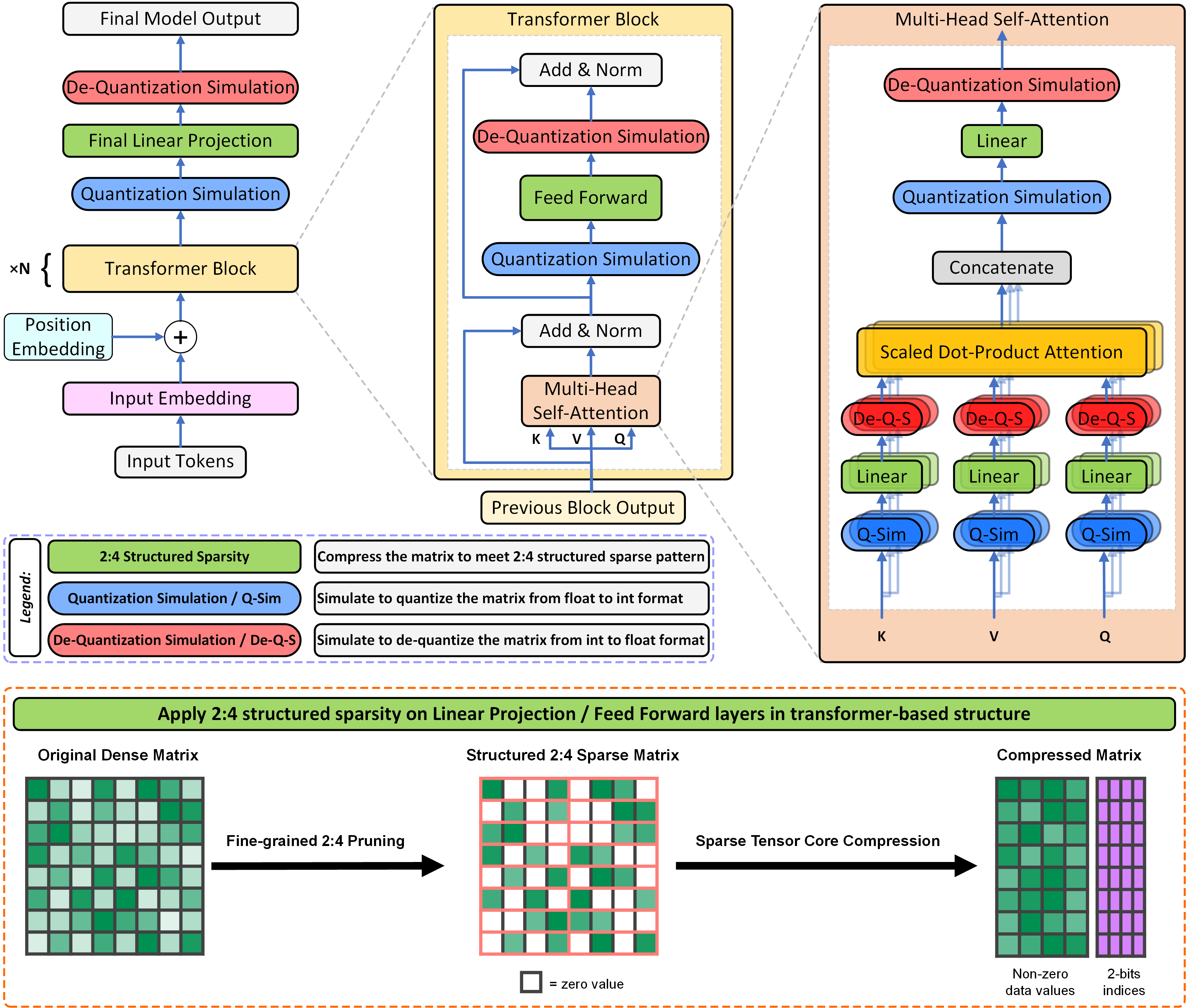
图2. 如何对基于Transformer结构的自然语言模型进行结构化稀疏和量化压缩
基于上面的分析,我们提出了面向GPU稀疏与量化的模型压缩方案,简称为GPUSQ-TLM。GPUSQ-TLM方案主要分成两个阶段,第一阶段是结构化剪枝,目的在于将原始的Transformer自然语言模型的密集浮点权重参数(MDF),在混合精度微调过程中逐步裁剪成稀疏浮点权重参数(MSF),以满足GPU对稀疏模式的加速约束。第二阶段是稀疏性已知的低精度量化过程,在这个过程中,通过量化感知训练将稀疏浮点权重参数(MSF)量化压缩为稀疏定点模型的权重参数(MSQ),来最大限度地利用GPU的张量运算核对低精度张量提供额外加速。在第一阶段的剪枝和第二阶段的量化过程中,均采用混合策略对自然语言模型的预测标签、预测概率分布和特征图进行加权知识蒸馏,以获得对GPUSQ-TLM压缩模型最佳的精度补偿效果。
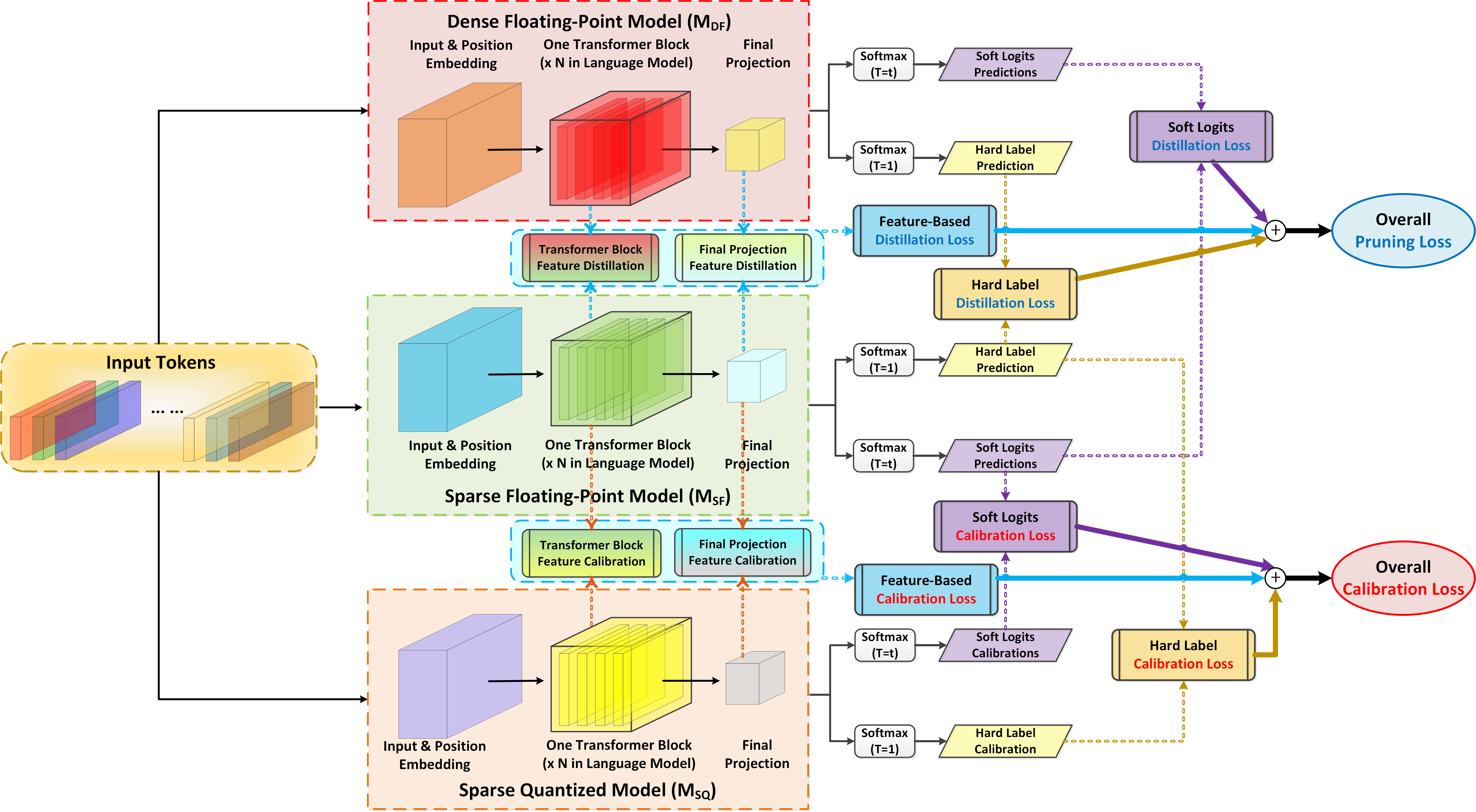
图3. GPUSQ-TLM模型压缩方案详细流程图
相关实验结果:
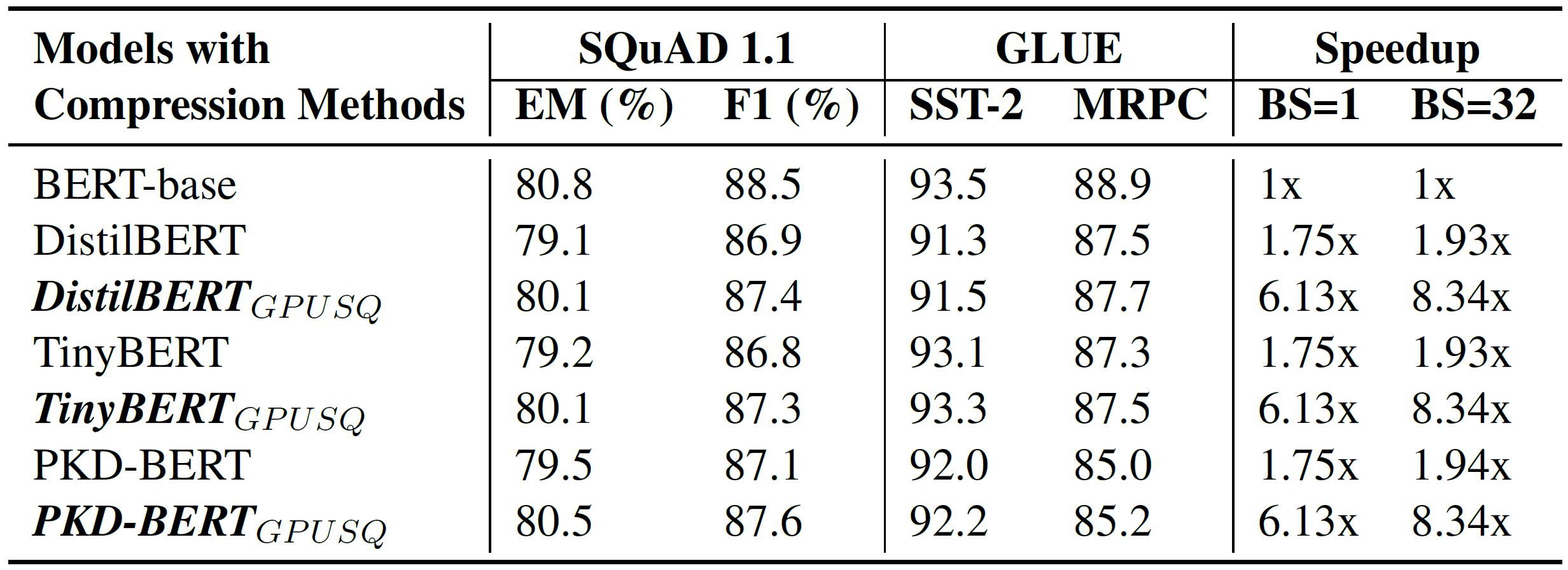
首先,我们选取了当前最先进和最具代表性的一些模型压缩策略作为对比,测试了这些压缩策略和GPUSQ-TLM模型压缩方案在典型的只有Transformer编码器结构的自然语言模型BERT-base和BERT-Large上的效果,如表1所示。
表1. 模型压缩策略在典型的Transformer编码器结构NLP模型上的有效性测试
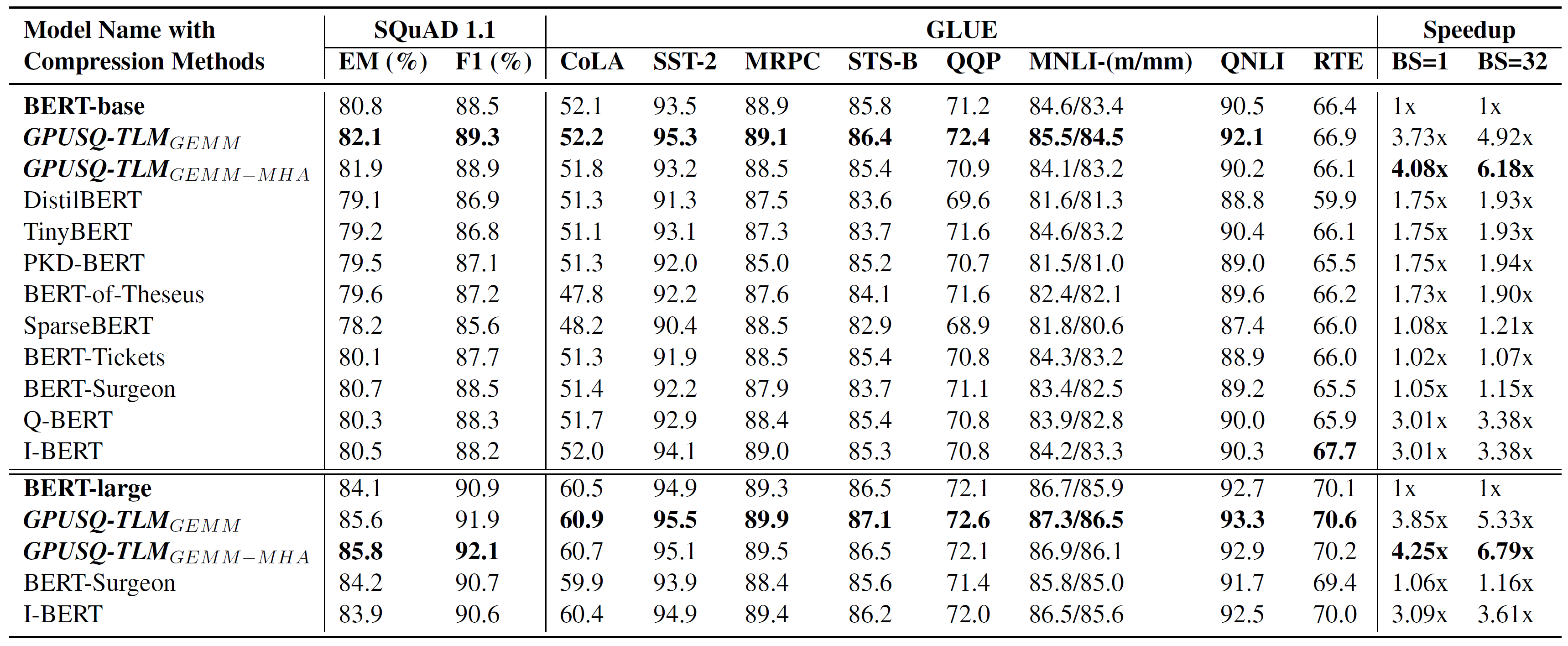
从表1所示的结果中,我们可以得出两个结论。首先,GPUSQ-TLM方案压缩得到的模型在SQuAD和GLUE基准测试中,精度性能和原始的BERT模型几乎一致,同时又明显优于其他的模型压缩策略所得到的模型。
此外,由于在模型压缩的方案中充分考虑了GPU可加速的稀疏和量化范式,因此GPUSQ-TLM方案可以在A100 GPU上将Transformer编码器结构自然语言模型实际延迟和吞吐的部署性能分别提高4.08-4.25倍和6.18-6.79倍。这一加速效果要远胜于先前的各种模型压缩策略。
接着,我们测试了一些有代表性的压缩策略和GPUSQ-TLM模型压缩方案在典型的只有Transformer解码器结构的自然语言模型OPT和GPT上的效果对比,如表2所示。
表2. 模型压缩策略在典型的Transformer解码器结构NLP模型上的有效性测试
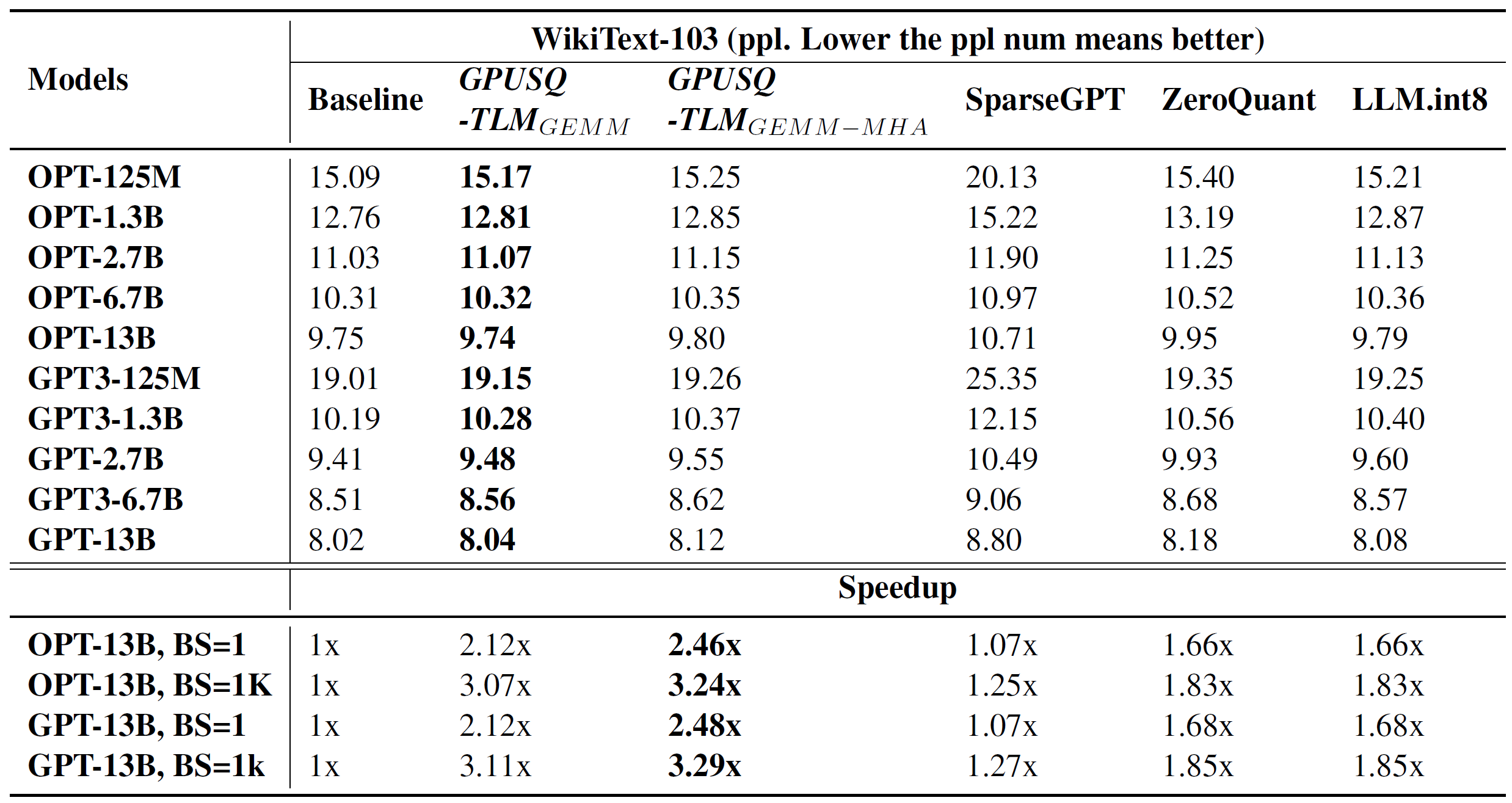
从表2所示的结果中,我们可以看到,GPUSQ-TLM方案压缩得到的模型在WikiText-103基准测试中,精度性能和原始的OPT与GPT模型相差无几,同时又明显优于其他的模型压缩策略所得到的模型。此外,GPUSQ-TLM方案可以在A100 GPU上将Transformer解码器结构自然语言模型实际延迟和吞吐的部署性能分别提高2.46-2.48倍和3.24-3.29倍。同样,这一加速效果要远胜于先前的各种模型压缩策略。
此外,我们还测试了GPUSQ-TLM模型压缩方案在典型的Transformer编解码混合结构的自然语言模型BART上的效果对比,如表3所示。
表3. 模型压缩策略在典型的Transformer编解码混合结构NLP模型上的有效性测试
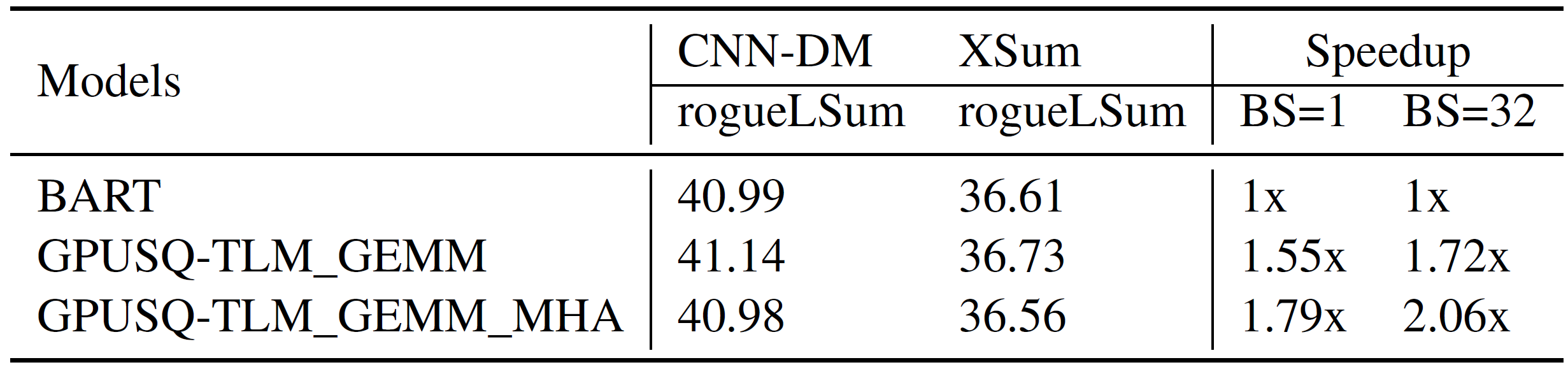
从表3所示的结果中,我们可以看到,GPUSQ-TLM方案压缩得到的模型在CNN-DM和XSum基准测试中,精度性能和原始的BART模型几乎一致。同时,GPUSQ-TLM方案可以在A100 GPU上将Transformer编解码混合结构自然语言模型实际延迟和吞吐的部署性能分别提高1.55-1.79倍和1.72-2.06倍。
由于之前的一些模型剪枝策略仅考虑将整个Transformer结构块整体去除,并没有考虑对结构块中的各层操作进行细粒度剪枝。因此,对于先前这些粗粒度模型剪枝策略,GPUSQ-TLM方案可以进一步将Transformer结构块中的各层压缩成GPU可加速的稀疏和量化格式,如表4所示。
表4. GPUSQ-TLM模型压缩方案在先前粗粒度模型剪枝策略上的叠加有效性测试
从表4所示的结果中,我们发现GPUSQ-TLM模型压缩方案可以在GPU上进一步加速这些粗粒度剪枝得到的模型,并且不会带来任何的精度损失。
延伸阅读:
ACL会议内容主要围绕自然语言对话、信息抽取、信息检索、语言生成、机器翻译、自动问答、语音学等多个方面,是自然语言处理与计算语言学领域最高级别的学术会议,由计算语言学协会主办,每年一届。中国计算机学会(CCF)推荐国际学术会议目录将ACL列为人工智能领域A类会议。
MAGIC Lab,是复旦大学工研院智能机器人研究院和智能机器人教育部工程研究中心的主要研究团队之一,复旦大学工研院副院长、智能机器人研究院院长甘中学教授为实验室首席PI。MAGIC Lab主要依托上海市人工智能市级重大专项,面向国家《新一代人工智能发展规划》中的群体智能理论、自主协同控制与优化决策理论、群体智能关键技术等重要科学方向,融合非线性动力学、模式识别、计算神经科学、强化学习、集群智能等多领域的理论与方法,重点探究人机物协同与智能融合的科学原理,突破异构群体行为协作与动态演变的关键技术,构建智慧交通与智能制造等场景下的异构集群交互系统。
地址:上海市杨浦区邯郸路220号 邮编:200433 电话:(86)021-65642222
Copyright©2016复旦大学版权所有 沪ICP备:16018209
 工研院二维码
工研院二维码
 研究生会二维码
研究生会二维码