新闻动态



近日,复旦大学工程与应用技术研究院(简称工研院)认知与智能技术实验室(简称CITLab)撰写的题为《PediatricsGPT: Large Language Models as Chinese Medical Assistants for Pediatric Applications》的成果被CCF-A类机器学习国际顶级学术会议NeurIPS 2024录用。20级直博生杨鼎康和23级硕士生魏金杰为第一作者,张立华教授和翟鹏博士后为通讯作者。
成果简介
当前,构建智能医疗会诊系统为提高疾病诊断效率提供了良好的前景,尤其是在医疗资源不足的中国。尽管中文医学大语言模型(LLMs)最近取得了进展,但由于训练语料质量参差不齐和训练程序在实际落地时存在诸多挑战,导致LLMs在儿科垂域和通用医疗应用中的表现并不理想。为了解决上述问题,本研究依托课题组主持的科技创新2030-“新一代人工智能”重大项目-“标准化儿童患者模型关键技术与应用”中丰富的医疗资源,构建了国内首个支持持续预训练、监督微调以及偏好优化阶段的高质量大规模语料库PedCorpus。PedCorpus的优越性体现在如下维度:
1.持续预训练语料囊括了来自96个专业儿科垂域和通识医疗教科书、指南,疾病特定的知识图谱,包含11个儿科大类中的131个细粒度病种;
2.多任务监督微调数据覆盖4个主要儿科应用中的16种丰富意图。针对多元化的数据资源,引入角色扮演驱动的指令构建规则以确保模型响应的准确性和人文主义性;设计上下文-自指令协同法则以确保模型生成的内容符合专业医生风格的同时具备用户患者友好性;提出渐进式的指令重构机制以确保富有信息量和逻辑流畅的模型响应;
3.偏好优化数据覆盖自认知、反事实以及对抗性指令,以满足真实场景下多元化的意图对齐需求。
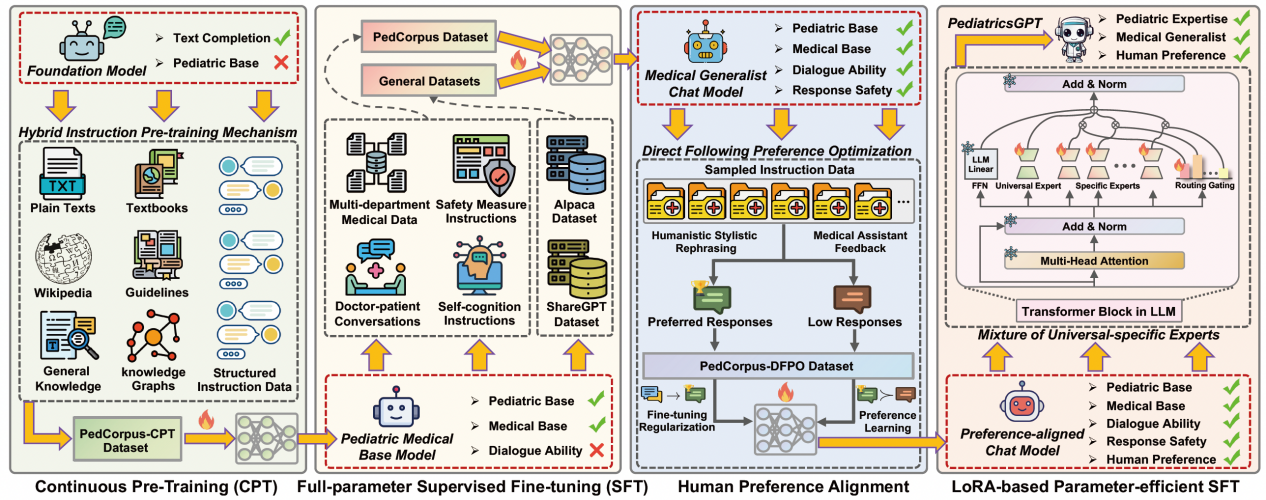
图1 系统性的医疗垂域模型构建框架
基于PedCorpus,该研究提出了一套系统性的训练管道以构建国内首个儿科专精和医疗通才的中文医学大语言模型助手PediatricsGPT。PediatricsGPT的可靠性和优势体现在如下维度:
1.引入了定制化的混合指令预训练策略,以桥接在多阶段训练中由于数据分布和语料格式体裁差异导致模型出现灾难性遗忘的问题;
2.提出了原型引导的通用-特定混合专家结构,以解决多任务意图之间的知识冲突和垂域-通用知识掌握时的技能冲突;
3.设计了直接遵循的偏好优化机制,通过正则化模型行为边界,促进鲁棒和平滑的人类偏好对齐。
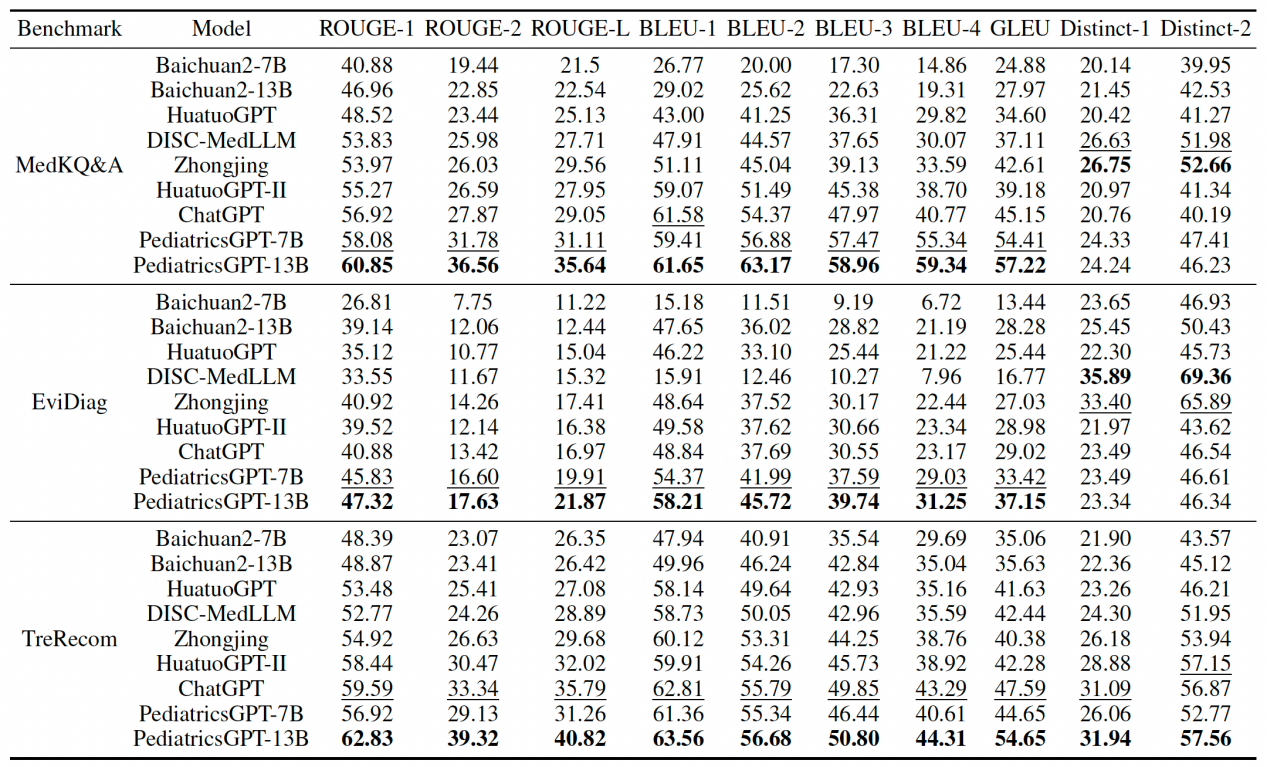
图2 多样化的指标评估结果
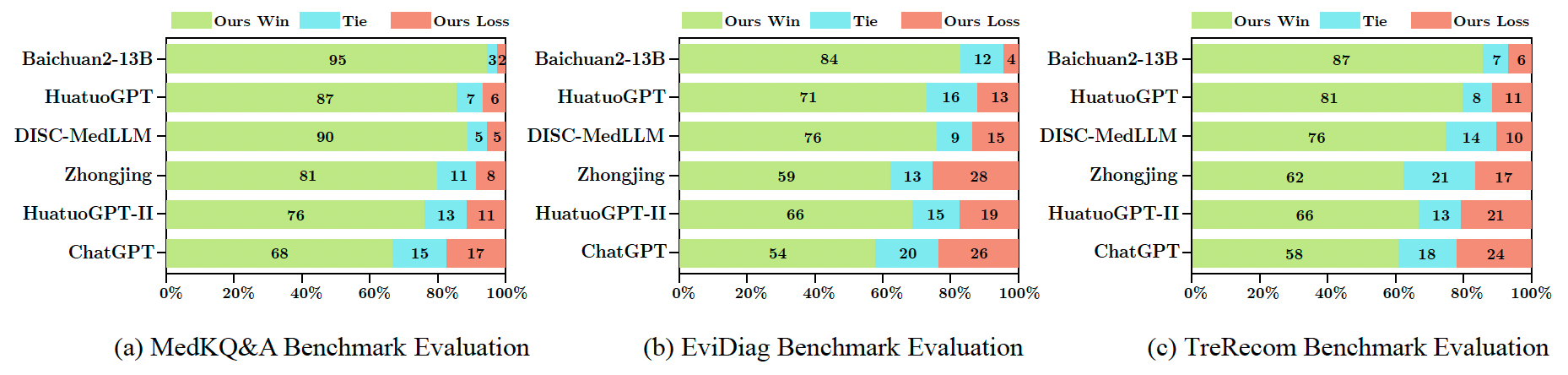
图3 GPT-4评估结果
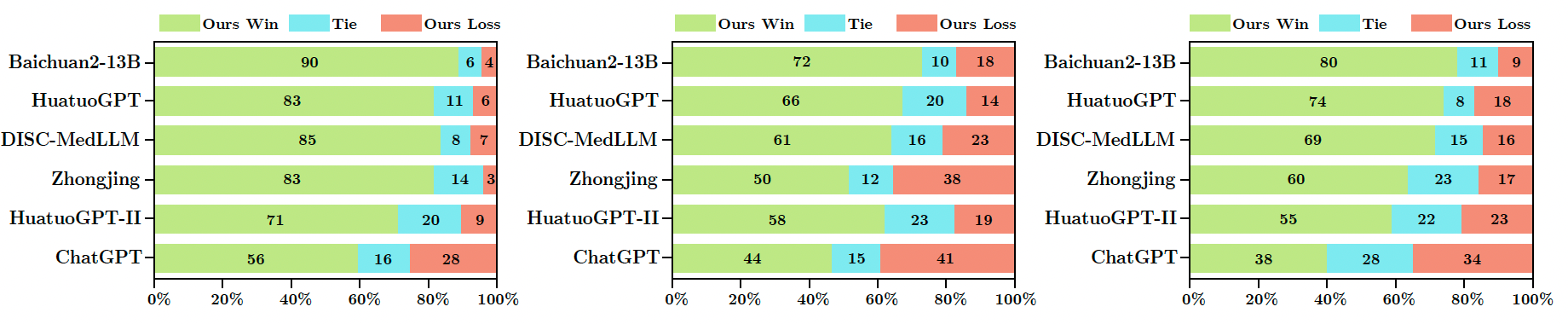
图4 专业医生评估结果
通过多样化的指标性、GPT-4以及专业医生评估,PediatricsGPT的7B和13B版本在多个科室特定和通用医疗基准上以显著的性能优于当前开源可复现的中文医疗LLMs和基线模型。

审稿人一致评价这项研究成果在中国儿科医疗LLMs的发展中具有里程碑的意义,并称赞提出的创新训练方法。该模型的多模态系列和以其为核心的医疗Agent框架将在后续逐步推出,以持续为多维度、交互式诊疗系统的落地部署和应用提供可靠的基座模型支撑。
延伸阅读
认知与智能技术实验室(简称CITLab)隶属于复旦大学工程与应用技术研究院智能机器人研究院,近年来一直在机器直觉、人机融合智能等新一代人工智能理论、脑机解码与脑启发人工智能、智能感知与人机交互、物理仿真与数字孪生、行为识别和情感分析以及大语言模型、智能机器人、智能驾驶、智能医学等领域开展交叉创新研究,相关学术成果发表于Nature主刊、中国科学、TPAMI、KBS、RAL、NeurIPS,CVPR、ICCV、ECCV、AAAI、ACM MM以及ICRA、IROS等国内外顶级期刊与会议。
NeurIPS(Annual Conference on Neural Information Processing Systems)是世界范围内机器学习领域的重要盛会。该会议是中国计算机学会推荐的CCF-A类顶级国际学术会议,每一年举办一次。
地址:上海市杨浦区邯郸路220号 邮编:200433 电话:(86)021-65642222
Copyright©2016复旦大学版权所有 沪ICP备:16018209
 工研院二维码
工研院二维码
 研究生会二维码
研究生会二维码