新闻动态



2025年1月,工研院甘中学教授课题组集群机器人系统实验室(Multi-AGent robotIC systems Lab,简称MAGIC Lab)在生物医学和健康信息学领域的国际顶级期刊(IEEE Journal of Biomedical and Health Informatics,简称IEEE JBHI)上发表医学图像处理领域的最新研究成果。复旦大学工研院2023级博士生孟春雷为第一作者,欧阳春青年副研究员、甘中学教授为通讯作者,发表题为《RTS-ViT: Real-Time Share Vision Transformer for Image Classification》的学术论文。
论文简介:
近年来,Vision Transformer (ViT)在图像分类领域取得了显著进展,因其无卷积结构和自注意力机制在多个基准测试中展现了与传统卷积神经网络 (CNN) 相当甚至更优的性能。虽然在大型数据集(如 ImageNet21K 和 JFT300M)上进行预训练可以显著提高性能,但 ViT成功的关键还在于其内在的特征学习能力。因此,研究如何在不依赖预训练条件下提升 ViT的特征学习效果成为研究热点。现有方法如 Cross-ViT 和 Dual-ViT 主要在最后编码阶段进行双分支特征融合,忽视了在中间编码阶段进行实时特征共享的潜力,导致对多尺度特征的捕获不足,从而限制了整体特征表达能力。为了有效利用不同编码阶段的互补特征表示,我们提出了一种双分支视觉变换器框架RTS-ViT,旨在通过利用实时共享特征来提高图像分类效果。
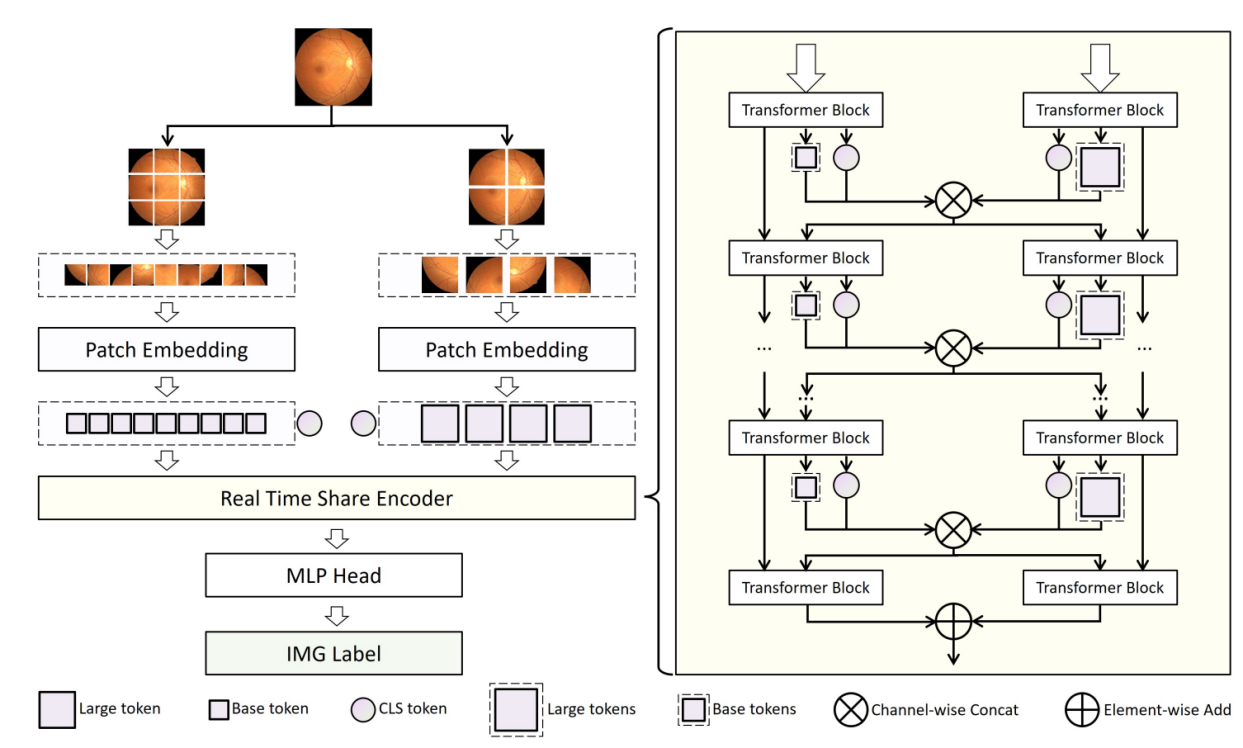
图1. RTS-ViT框架图
如图1所示,RTS-ViT通过两个独立的分支处理不同大小(base和large)的图像块,并通过Real-Time Share Encoder实现多阶段实时特征融合。Real-Time Share Encoder使双分支在每个编码阶段能够互补彼此的特征,促进更精细的特征学习并增强传递到后续阶段的自注意力信息。这种设计增强了模型捕获复杂、细粒度模式的能力,特别是提高了视网膜图像分类性能。
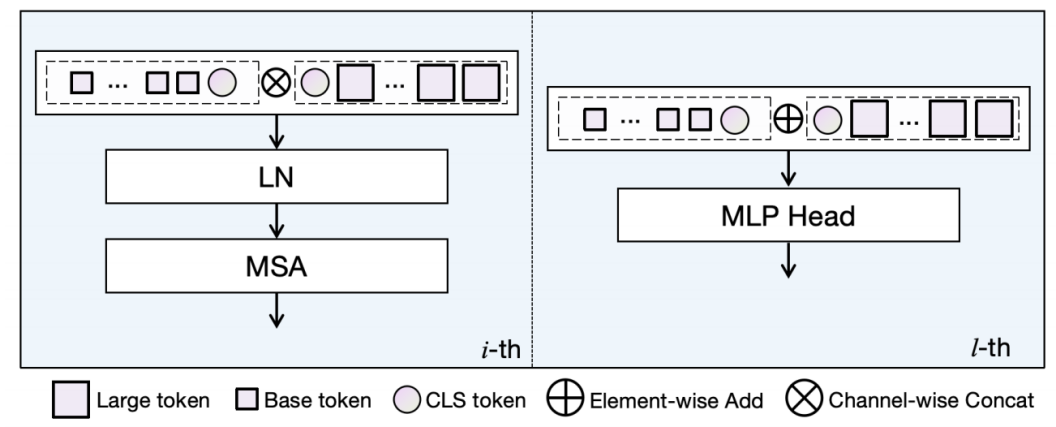
图2. L-Times Attention Fusion
此外,如图2所示,我们还提出了一种简单有效的特征融合方法L-Times Attention Fusion。在前(L-1)编码阶段对实时共享特征进行向量串联,在第L阶段对整体特征融合进行元素相加,可在每个编码阶段实现高效且全面的特征集成。
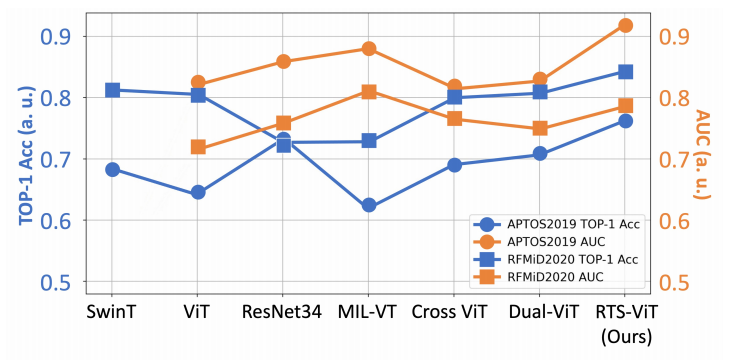
图3. RTS-ViT与baseline在视网膜图像数据集上效果对比
如图3和图4所示,在视网膜等图像数据集上进行了大量实验,结果表明RTS-ViT表现优异。具体而言,RTS-ViT在模型复杂度显著降低(2.19M Params,0.1 GFLOPs)的情况下,TOP-1平均准确率比最新的Cross-ViT提升了5.61%。此外,在AUC指标上,RTS-ViT较最新的Dual-ViT模型平均提升了6.335%,充分展示了其不依赖预训练的情况下卓越的特征学习能力和轻量化临床部署的潜力。
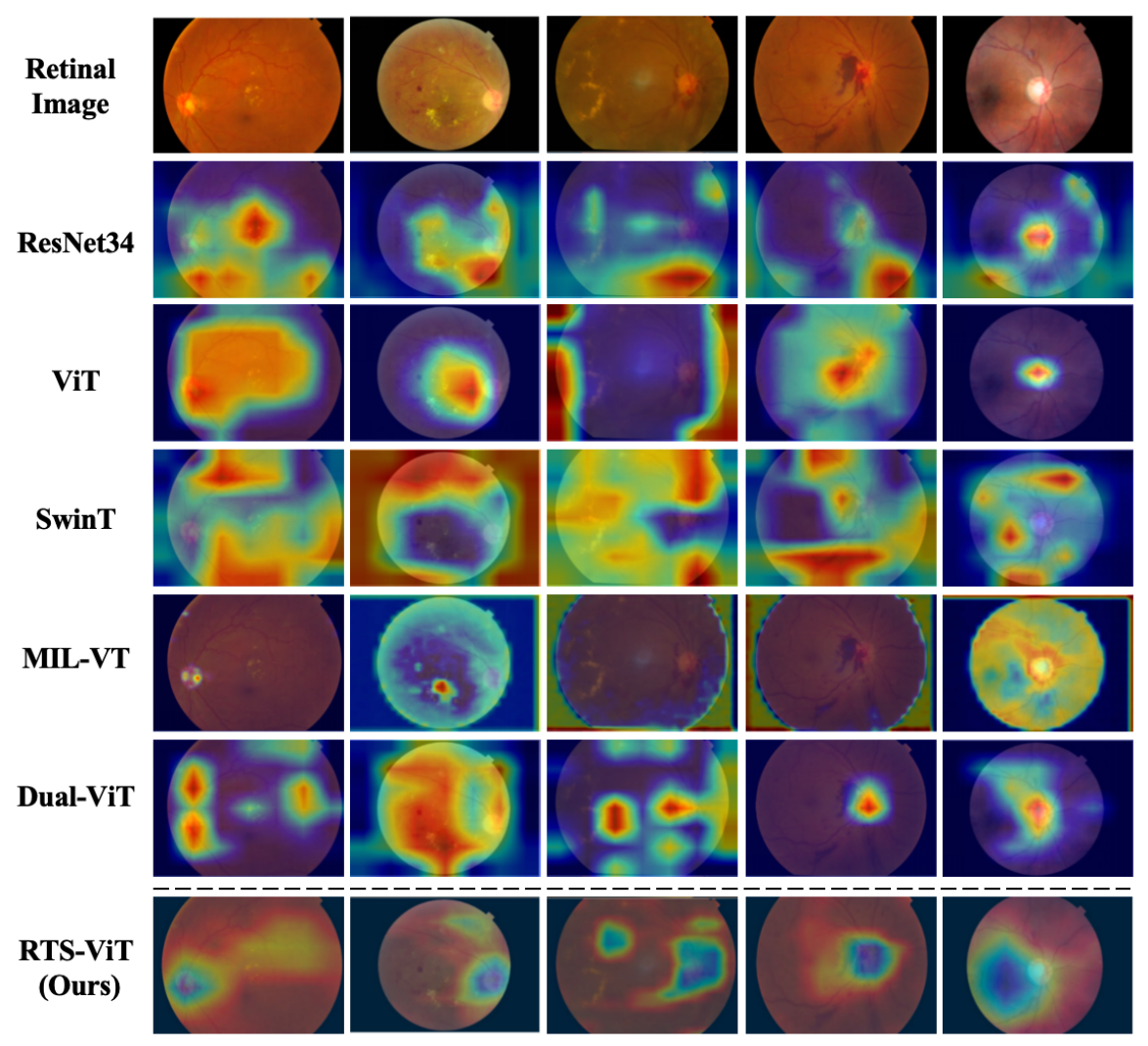
图4. RTS-ViT与baseline在视网膜图像数据集上可视化效果
原文链接:https://ieeexplore.ieee.org/document/10820101
延伸阅读:
《IEEE Journal of Biomedical and Health Informatics》由IEEE出版,是国际公认的生物医学和健康信息学领域的国际顶级期刊,重点专注生命科学和生物医学交叉的研究,为SCI一区Top期刊,中国科协高质量科技T1类期刊。
MAGIC Lab,是复旦大学工研院智能机器人研究院和智能机器人教育部工程研究中心的主要研究团队之一,复旦大学工研院副院长、智能机器人研究院院长甘中学教授为实验室首席PI。MAGIC Lab主要依托上海市人工智能市级重大专项,面向国家《新一代人工智能发展规划》中的群体智能理论、自主协同控制与优化决策理论、群体智能关键技术等重要科学方向,融合非线性动力学、模式识别、计算神经科学、强化学习、集群智能等多领域的理论与方法,重点探究人机物协同与智能融合的科学原理,突破异构群体行为协作与动态演变的关键技术,构建智慧交通与智能制造等场景下的异构集群交互系统。
地址:上海市杨浦区邯郸路220号 邮编:200433 电话:(86)021-65642222
Copyright©2016复旦大学版权所有 沪ICP备:16018209
 工研院二维码
工研院二维码
 研究生会二维码
研究生会二维码